Email: [email protected] 7 x 24 online support!
MySQL中恢复/修复InnoDB数据字典
c_parser 是工具包中的一个命令行工具,它能读取 InnoDB 页面并从中获取记录。虽然它可以扫描任何字节流,但恢复质量比你将属于表的PRIMARY索引的页面提供给 c_parser 更高。所有InnoDB索引有自己的标识符,又名index_id。InnoDB字典储存表名和index_id之间的对应关系。这是第一个原因。
另一个原因是InnoDB字典能恢复表结构。当一个表被删除,MySQL删除相应的.frm文件。如果你既没有备份,又没有表schema,恢复该表结构就有相当大的困难。这个话题需要我哪天再写一篇单独的文章来讲。
假设你对以上足够确信,我们就能继续InnoDB字典的恢复了。
拆分 ibdata1
InnoDB 字段储存在 ibdata1中,所以我们需要分析它并获取存放字典记录的页面。使用 stream_parser 。
# ./stream_parser -f /var/lib/mysql/ibdata1 ... Size to process: 79691776 (76.000 MiB) All workers finished in 1 sec
stream_parser 找出在ibdata1 中的InnoDB 页面,将它们以页面类型(FIL_PAGE_INDEX 或FIL_PAGE_TYPE_BLOB) , index_id.的顺序储存。
索引如下:
SYS_TABLES [root@twindb-dev undrop-for-innodb]# ll pages-ibdata1/FIL_PAGE_INDEX/0000000000000001.page -rw-r--r-- 1 root root 16384 Jun 24 00:50 pages-ibdata1/FIL_PAGE_INDEX/0000000000000001.page SYS_INDEXES [root@twindb-dev undrop-for-innodb]# ll pages-ibdata1/FIL_PAGE_INDEX/0000000000000003.page -rw-r--r-- 1 root root 16384 Jun 24 00:50 pages-ibdata1/FIL_PAGE_INDEX/0000000000000003.page SYS_COLUMNS [root@twindb-dev undrop-for-innodb]# ll pages-ibdata1/FIL_PAGE_INDEX/0000000000000002.page -rw-r--r-- 1 root root 49152 Jun 24 00:50 pages-ibdata1/FIL_PAGE_INDEX/0000000000000002.page 和 SYS_FIELDS [root@twindb-dev undrop-for-innodb]# ll pages-ibdata1/FIL_PAGE_INDEX/0000000000000004.page -rw-r--r-- 1 root root 16384 Jun 24 00:50 pages-ibdata1/FIL_PAGE_INDEX/0000000000000004.page
可以看到字典较小,每个索引只有一页。
从 SYS_TABLES 和 SYS_INDEXES转储(dump)记录
要从索引页提取记录,你需要使用 c_parser。但首先,我们来创建转储的目录:
[root@twindb-dev undrop-for-innodb]# mkdir -p dumps/default [root@twindb-dev undrop-for-innodb]#
InnoDB 字典总是 REDUNDANT 格式,所以选项 -4 是强制的:
[root@twindb-dev undrop-for-innodb]# ./c_parser -4f pages-ibdata1/FIL_PAGE_INDEX/0000000000000001.page -t dictionary/SYS_TABLES.sql > dumps/default/SYS_TABLES 2> dumps/default/SYS_TABLES.sql [root@twindb-dev undrop-for-innodb]#
这是我们的sakila 表:
[root@twindb-dev undrop-for-innodb]# grep sakila dumps/default/SYS_TABLES | head -5 0000000052D5 D9000002380110 SYS_TABLES "sakila/actor" 753 4 1 0 80 "" 739 0000000052D8 DC0000014F0110 SYS_TABLES "sakila/address" 754 8 1 0 80 "" 740 0000000052DB DF000002CA0110 SYS_TABLES "sakila/category" 755 3 1 0 80 "" 741 0000000052DE E2000002F80110 SYS_TABLES "sakila/city" 756 4 1 0 80 "" 742 0000000052E1 E5000002C50110 SYS_TABLES "sakila/country" 757 3 1 0 80 "" 743 [root@twindb-dev undrop-for-innodb]#
dumps/default/SYS_TABLES 是符合 LOAD DATA INFILE命令的表转储。具体命令 c_parsers 打印到标准错误输出。我将它保存在dumps/default/SYS_TABLES.sql
[root@twindb-dev undrop-for-innodb]# cat dumps/default/SYS_TABLES.sql SET FOREIGN_KEY_CHECKS=0; LOAD DATA INFILE '/root/tmp/undrop-for-innodb/dumps/default/SYS_TABLES' REPLACE INTO TABLE `SYS_TABLES` FIELDS TERMINATED BY '\t' OPTIONALLY ENCLOSED BY '"' LINES STARTING BY 'SYS_TABLES\t' (`NAME`, `ID`, `N_COLS`, `TYPE`, `MIX_ID`, `MIX_LEN`, `CLUSTER_NAME`, `SPACE`); [root@twindb-dev undrop-for-innodb]# 我们以相同方式转储 SYS_INDEXES: [root@twindb-dev undrop-for-innodb]# ./c_parser -4f pages-ibdata1/FIL_PAGE_INDEX/0000000000000003.page -t dictionary/SYS_INDEXES.sql > dumps/default/SYS_INDEXES 2> dumps/default/SYS_INDEXES.sql [root@twindb-dev undrop-for-innodb]# [root@twindb-dev undrop-for-innodb]# head -5 dumps/default/SYS_INDEXES -- Page id: 11, Format: REDUNDANT, Records list: Valid, Expected records: (153 153) 000000000300 800000012D0177 SYS_INDEXES 11 11 "ID\_IND" 1 3 0 302 000000000300 800000012D01A5 SYS_INDEXES 11 12 "FOR\_IND" 1 0 0 303 000000000300 800000012D01D3 SYS_INDEXES 11 13 "REF\_IND" 1 0 0 304 000000000300 800000012D026D SYS_INDEXES 12 14 "ID\_IND" 2 3 0 305 [root@twindb-dev undrop-for-innodb]# head -5 dumps/default/SYS_INDEXES.sql SET FOREIGN_KEY_CHECKS=0; LOAD DATA INFILE '/root/tmp/undrop-for-innodb/dumps/default/SYS_INDEXES' REPLACE INTO TABLE `SYS_INDEXES` FIELDS TERMINATED BY '\t' OPTIONALLY ENCLOSED BY '"' LINES STARTING BY 'SYS_INDEXES\t' (`TABLE_ID`, `ID`, `NAME`, `N_FIELDS`, `TYPE`, `SPACE`, `PAGE_NO`); [root@twindb-dev undrop-for-innodb]#
现在用字典操作了,如果表在MySQL中会更方便。
将字典表加载到 MySQL中
SYS_TABLES 和 SYS_INDEXES 的主要用途是根据表名获取 index_id。运行两个 greps是可能的。SYS_TABLES 和 SYS_INDEXES 在MySQL中会使操作更简便。
Before we can process let’s make sure mysql user can read from the root’s home directory. Maybe it’s not wise from security standpoint. If it’s your concern create whole recovery environment somewhere in /tmp. 在操作之前,我们要确保MySQL用户可以从root的主目录中读取。从安全角度来看,这也许不太明智。如果你对此有所顾虑,你可以在/ tmp目录某处创建整个恢复环境。
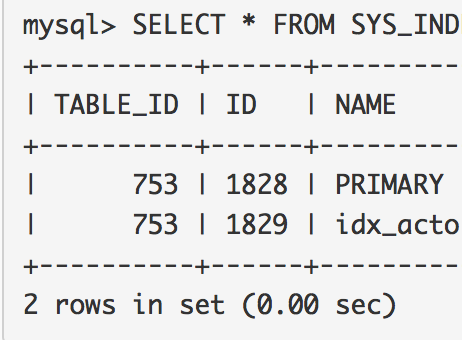
[root@twindb-dev undrop-for-innodb]# chmod 711 /root/ [root@twindb-dev undrop-for-innodb]# 在某些数据库中创建空字典表(例: test) [root@twindb-dev undrop-for-innodb]# mysql test < dictionary/SYS_TABLES.sql 在某些数据库中创建空字典表(例: test) [root@twindb-dev undrop-for-innodb]# mysql test < dictionary/SYS_TABLES.sql 并加载转储数据: [root@twindb-dev undrop-for-innodb]# mysql test < dumps/default/SYS_TABLES.sql [root@twindb-dev undrop-for-innodb]# mysql test < dumps/default/SYS_INDEXES.sql [root@twindb-dev undrop-for-innodb]# 现在InnoDB 字典在MySQL 中,我们能以在任何其他MySQL表中的方式查询它: mysql> SELECT * FROM SYS_TABLES WHERE NAME = 'sakila/actor'; +--------------+-----+--------+------+--------+---------+--------------+-------+ | NAME | ID | N_COLS | TYPE | MIX_ID | MIX_LEN | CLUSTER_NAME | SPACE | +--------------+-----+--------+------+--------+---------+--------------+-------+ | sakila/actor | 753 | 4 | 1 | 0 | 80 | | 739 | +--------------+-----+--------+------+--------+---------+--------------+-------+ 1 row in set (0.00 sec) mysql> SELECT * FROM SYS_INDEXES WHERE TABLE_ID = 753; +----------+------+---------------------+----------+------+-------+---------+ | TABLE_ID | ID | NAME | N_FIELDS | TYPE | SPACE | PAGE_NO | +----------+------+---------------------+----------+------+-------+---------+ | 753 | 1828 | PRIMARY | 1 | 3 | 739 | 3 | | 753 | 1829 | idx_actor_last_name | 1 | 0 | 739 | 4 | +----------+------+---------------------+----------+------+-------+---------+ 2 rows in set (0.00 sec)
我们看到sakila.actor 有两个索引: PRIMARY 和idx_actor_last_name。index_id 分别是1828 和1829。
如果自己搞不定可以找诗檀软件专业ORACLE/MySQL数据库修复团队成员帮您恢复!
诗檀软件专业数据库修复团队
服务热线 : 13764045638 QQ号:47079569 邮箱:[email protected]
Copyright © 2013, 2023, parnassusdata.com. 版权所有。dbrecover.com
 沪公网安备 31010802001377号
沪公网安备 31010802001377号